
Predictive Data Modeling Part II: An Illustrated Guide to The Mathematics of Bayesian Improved First Name Surname Geocoding (BIFSG)
In a previous blog, I shared a bit of my exploration into the Bayesian Improved First Name Surname Geocoding (BIFSG) method for imputing race probabilities given a person’s first name, surname and ZIP code. In this new blog, I would like to share the mathematics of BIFSG. I will use myself as the subject of the model, in an effort that I hope will make the mathematics easier to follow and understand.
A quick Google search returned nine Gary Wangs in six cities in the State of Illinois (www.whitepages.com). A listing showing all ZIP code, surname and first name combinations would likely make me a unique listing in that database. Such a dataset raises privacy issues by making my personal information visible to the analyst, creating a mountain of work to keep up to date, and leaving open the question of what to do when a person’s particular name/ZIP code combination is not found in the list.
BIFSG is an approach to provide race information without resorting to using the above privacy-encroaching dataset. To illustrate the math behind BIFSG, we will walk through how we might go about determining the probability that I belong to one of a variety of race and ethnic groups:
First Name = Gary
Surname = Wang
Zip Code = 61704
The focus will be my racial group “Asian/Pacific Islander” (API). However, we will carry out the calculations sufficient to determine the probabilities for my potential inclusion in each of the six racial and ethnic groups (White, Black, Asian or Pacific Islander (API), Native American, Multiple Race, Hispanic), since we’ll need all the numbers for our computations.
The following is a walk-through of the mathematics behind BIFSG. Those more interested in the intuitive understanding of the method, may certainly jump ahead past the formulas and get straight to the “punchline,” below.
The starting formula for the probability for me to belong to group API would be:
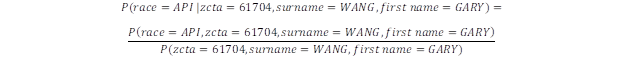
That is, out of all instances (or, people) with the GARY-WANG-61704 combination, how many are also in the race group API? Technically, there is a step between a formula showing a ratio of probabilities and the description referring to a ratio of counts. However, since this is a blog, I’m entitling myself to a certain amount of latitude in equating these two. We will also use the terms “proportion” and “probability” interchangeably.
One key observation is that if we get the numerator term for each of the six race groups, the sum total of those six terms would be the denominator. That is, our effort comes down to being able to derive P(race = i,zcta = 61704, surname = WANG, first name = GARY) for each race group i.
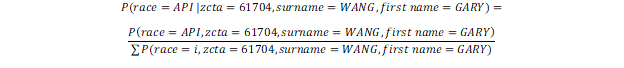
To determine the numerator term, we can use the chain rule for probabilities:

That is, we begin with the probability a person is in ZIP code 61704. The second term reflects that we can see that the person is included in that ZIP code and with that knowledge ask the chance that person is also of race API. The build-up of the probabilities continues in this manner—where we establish that we know some of the information and ask the probability of the next piece of information matching our record, once we know everything matches before it. By the time we reach the final term, we can see all four pieces of information that establish probability.
Now, we make some assumptions of independence. We assume that the probability of surname WANG does not depend on ZIP code, and the probability of first name GARY does not depend on surname or on location. These assumptions of independence allow us to simplify two of the above probabilities. First:
A way to interpret the above is that we don’t need to know the proportion of people in the race group API in ZIP code 61704 that have the surname WANG. Instead, we approximate by asking what proportion of people in the race group API in the United States have the surname WANG. The information aggregated at the countrywide level would ensure greater anonymity than at the ZIP code level.
Similarly:
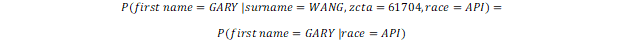
Here, the difference in preserving privacy is even more pronounced. Instead of requiring a summary of GARY-WANG-61704-API combinations (likely unique) as a proportion of WANG-61704-API combinations (a very small sample), we only ask what proportion of the API population in the U.S. that have GARY as first name.
Using the above assumptions, our formula simplifies to:

Our formula, with the above algebra and simplification, becomes:
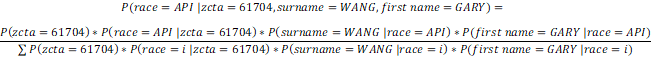
We observe P (zcta = 61704) is in every term of the numerator and denominator. The ratio then reduces to:
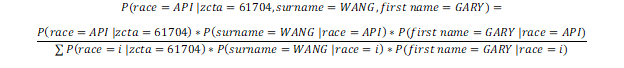
And here’s the punchline. Through the use of the Bayesian Formula and some well-placed independence assumptions, the need of a detailed four-column table listing ZIP code, surname, first name and race is replaced with needing three pairwise tables summarizing each of ZIP code, surname and first name with race.
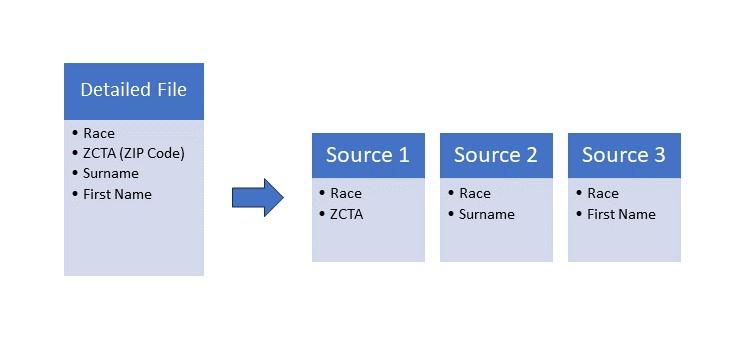
When aggregated and limited to locations or names that occur frequently enough (e.g., over 100 observations), the simpler tables should maintain enough anonymity to mitigate Personal Identifiable Information (PII)-related concerns. We give up accuracy through having exact information in return for the ability to use approximated labels using simpler aggregated data.
From the documentation for the Python package SURGEO (https://surgeo.readthedocs.io/en/dev/) the three pairwise source files are available for our explorations:
- 2010 United Census Summary File 1 data set
- 2010 United Census Frequently Occurring Surnames data set; and,
- Demographics aspect of first names data set[1].
[1] Konstantinos Tzioumis, “Data for: Demographic aspects of first names”. Harvard Dataverse (2018), V1 https://doi.org/10.7910/DVN/TYJKEZ
Utilizing the tables and working out the numbers, we would arrive at the following computational table for GARY-WANG-61704 and each of the six race and ethnic groups:

The P(race | zcta) row is relatively easy to decipher. In ZIP code 61704, 74.4% of the people are white and 11.2% of the people are API, based on the 2010 census data. My record, using this information alone, would suggest that I be labeled as “white.” The next row, P(surname | race), is a little hard to intuit. I prefer to look at this information a slightly different way:
If we treat P(surname | race = white) as the base probability, and compute what other probabilities are relative to this base, we see that the surname WANG is 487 times as likely a surname for someone in the API segment of the population as it is for someone in the White segment of the population!
Let’s look at the same information for P(first name | race):
From the information above, we see that the first name GARY is more commonly a first name for someone in the white segment of the population than for someone in the API segment of the population. Together, the surname information greatly increases the likelihood of me being in the API group, and while the first name information decreases this value, it is nowhere near how the surname increases the probability. The two additional pieces of information, taken together with the initial ZIP code-based information, shift my probability of being API from 11.2% to 92.8%.
In my work, I have derived a different first-name-given-race table than the one utilized in the SURGEO package. Thus, if one checked my math using the SURGEO package, my numbers and the SURGEO package numbers do not reconcile. Any reader interested in learning more about the difference can reach out to me to talk through my formulations and where they differ from what is done within the SURGEO package code.
For completeness, here is the table for my wife, using her married name:

The main difference between my wife and I is that my wife’s first name is a relatively more common first name for the API segment than my first name (hers is a relativity of 0.46, while mine has a relativity of 0.26).
Had we been privy to the detailed race/zcta/surname/first name information, we would be able to find my wife’s married name-ZIP code combination and see that she is white. But the ability to do so comes at the cost of her private information being made accessible. The BIFSG approach has the issue of mislabeling her at 94.8% as being likely Asian. Conversely, the race probabilities model provides better race group probabilities for me, and others like me who are Asian with the Wang last name but live in a white-dominant ZIP code. Their first names may shift the probabilities somewhat, but Wang being such a prominent Asian surname results in significant adjustments of the ZIP code-based probabilities to increase the likelihood of the person being of race API, an adjustment that is more often right than wrong.
News & Insights

What Recessions Reveal About Property and Casualty Insurance Dynamics

How the Insurance Industry is Navigating the Complex Debate Over Fairness in Pricing

Keeping It Clean: Understanding Pollution Liability Insurance and Its Future
